Python Read in Png Image Normalize for Deep Neural Network
This tutorial focuses on the task of image segmentation, using a modified U-Net.
What is image segmentation?
In an image classification job the network assigns a characterization (or class) to each input epitome. However, suppose you want to know the shape of that object, which pixel belongs to which object, etc. In this case you will desire to assign a class to each pixel of the paradigm. This chore is known as sectionalisation. A partitioning model returns much more detailed data about the paradigm. Image segmentation has many applications in medical imaging, cocky-driving cars and satellite imaging to proper name a few.
This tutorial uses the Oxford-IIIT Pet Dataset (Parkhi et al, 2012). The dataset consists of images of 37 pet breeds, with 200 images per breed (~100 each in the training and exam splits). Each epitome includes the corresponding labels, and pixel-wise masks. The masks are form-labels for each pixel. Each pixel is given one of three categories:
- Class ane: Pixel belonging to the pet.
- Class ii: Pixel bordering the pet.
- Class 3: None of the above/a surrounding pixel.
pip install git+https://github.com/tensorflow/examples.git import tensorflow as tf import tensorflow_datasets equally tfds from tensorflow_examples.models.pix2pix import pix2pix from IPython.display import clear_output import matplotlib.pyplot every bit plt Download the Oxford-IIIT Pets dataset
The dataset is available from TensorFlow Datasets. The segmentation masks are included in version 3+.
dataset, info = tfds.load('oxford_iiit_pet:3.*.*', with_info=Truthful) In addition, the epitome color values are normalized to the [0,1] range. Finally, as mentioned above the pixels in the segmentation mask are labeled either {i, 2, 3}. For the sake of convenience, decrease 1 from the segmentation mask, resulting in labels that are : {0, 1, 2}.
def normalize(input_image, input_mask): input_image = tf.cast(input_image, tf.float32) / 255.0 input_mask -= 1 render input_image, input_mask def load_image(datapoint): input_image = tf.image.resize(datapoint['image'], (128, 128)) input_mask = tf.image.resize(datapoint['segmentation_mask'], (128, 128)) input_image, input_mask = normalize(input_image, input_mask) return input_image, input_mask The dataset already contains the required grooming and exam splits, so continue to use the same splits.
TRAIN_LENGTH = info.splits['railroad train'].num_examples BATCH_SIZE = 64 BUFFER_SIZE = 1000 STEPS_PER_EPOCH = TRAIN_LENGTH // BATCH_SIZE train_images = dataset['train'].map(load_image, num_parallel_calls=tf.data.AUTOTUNE) test_images = dataset['test'].map(load_image, num_parallel_calls=tf.data.AUTOTUNE) The following class performs a uncomplicated augmentation by randomly-flipping an image. Go to the Paradigm augmentation tutorial to acquire more.
class Augment(tf.keras.layers.Layer): def __init__(cocky, seed=42): super().__init__() # both use the same seed, and so they'll brand the same random changes. self.augment_inputs = tf.keras.layers.RandomFlip(mode="horizontal", seed=seed) self.augment_labels = tf.keras.layers.RandomFlip(fashion="horizontal", seed=seed) def phone call(self, inputs, labels): inputs = self.augment_inputs(inputs) labels = self.augment_labels(labels) render inputs, labels Build the input pipeline, applying the Augmentation subsequently batching the inputs.
train_batches = ( train_images .cache() .shuffle(BUFFER_SIZE) .batch(BATCH_SIZE) .repeat() .map(Augment()) .prefetch(buffer_size=tf.data.AUTOTUNE)) test_batches = test_images.batch(BATCH_SIZE) Visualize an image example and its corresponding mask from the dataset.
def brandish(display_list): plt.figure(figsize=(xv, xv)) title = ['Input Image', 'True Mask', 'Predicted Mask'] for i in range(len(display_list)): plt.subplot(one, len(display_list), i+1) plt.title(title[i]) plt.imshow(tf.keras.utils.array_to_img(display_list[i])) plt.axis('off') plt.show() for images, masks in train_batches.have(2): sample_image, sample_mask = images[0], masks[0] display([sample_image, sample_mask]) Decadent JPEG data: 240 extraneous bytes before marker 0xd9 Corrupt JPEG data: premature end of data segment


2022-01-26 05:14:45.972101: Due west tensorflow/cadre/kernels/data/cache_dataset_ops.cc:768] The calling iterator did not fully read the dataset being cached. In order to avoid unexpected truncation of the dataset, the partially cached contents of the dataset will be discarded. This can happen if you accept an input pipeline similar to `dataset.enshroud().take(g).repeat()`. You should apply `dataset.take(k).enshroud().echo()` instead.
Define the model
The model being used hither is a modified U-Net. A U-Cyberspace consists of an encoder (downsampler) and decoder (upsampler). In-guild to learn robust features and reduce the number of trainable parameters, you lot will use a pretrained model - MobileNetV2 - as the encoder. For the decoder, you will use the upsample cake, which is already implemented in the pix2pix example in the TensorFlow Examples repo. (Check out the pix2pix: Epitome-to-prototype translation with a conditional GAN tutorial in a notebook.)
Equally mentioned, the encoder will be a pretrained MobileNetV2 model which is prepared and ready to apply in tf.keras.applications. The encoder consists of specific outputs from intermediate layers in the model. Note that the encoder will not be trained during the grooming process.
base_model = tf.keras.applications.MobileNetV2(input_shape=[128, 128, three], include_top=False) # Utilize the activations of these layers layer_names = [ 'block_1_expand_relu', # 64x64 'block_3_expand_relu', # 32x32 'block_6_expand_relu', # 16x16 'block_13_expand_relu', # 8x8 'block_16_project', # 4x4 ] base_model_outputs = [base_model.get_layer(name).output for proper noun in layer_names] # Create the feature extraction model down_stack = tf.keras.Model(inputs=base_model.input, outputs=base_model_outputs) down_stack.trainable = False Downloading data from https://storage.googleapis.com/tensorflow/keras-applications/mobilenet_v2/mobilenet_v2_weights_tf_dim_ordering_tf_kernels_1.0_128_no_top.h5 9412608/9406464 [==============================] - 0s 0us/stride 9420800/9406464 [==============================] - 0s 0us/pace
The decoder/upsampler is simply a serial of upsample blocks implemented in TensorFlow examples.
up_stack = [ pix2pix.upsample(512, 3), # 4x4 -> 8x8 pix2pix.upsample(256, 3), # 8x8 -> 16x16 pix2pix.upsample(128, 3), # 16x16 -> 32x32 pix2pix.upsample(64, 3), # 32x32 -> 64x64 ] def unet_model(output_channels:int): inputs = tf.keras.layers.Input(shape=[128, 128, 3]) # Downsampling through the model skips = down_stack(inputs) 10 = skips[-ane] skips = reversed(skips[:-one]) # Upsampling and establishing the skip connections for upward, skip in zip(up_stack, skips): x = upwards(10) concat = tf.keras.layers.Concatenate() ten = concat([10, skip]) # This is the last layer of the model last = tf.keras.layers.Conv2DTranspose( filters=output_channels, kernel_size=3, strides=2, padding='aforementioned') #64x64 -> 128x128 ten = final(x) return tf.keras.Model(inputs=inputs, outputs=x) Note that the number of filters on the final layer is set to the number of output_channels. This volition exist one output channel per form.
Train the model
Now, all that is left to practise is to compile and railroad train the model.
Since this is a multiclass classification problem, utilise the tf.keras.losses.CategoricalCrossentropy loss office with the from_logits argument fix to Truthful, since the labels are scalar integers instead of vectors of scores for each pixel of every class.
When running inference, the label assigned to the pixel is the channel with the highest value. This is what the create_mask function is doing.
OUTPUT_CLASSES = 3 model = unet_model(output_channels=OUTPUT_CLASSES) model.compile(optimizer='adam', loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True), metrics=['accurateness']) Have a quick look at the resulting model compages:
tf.keras.utils.plot_model(model, show_shapes=True) 
Endeavor out the model to bank check what information technology predicts before training.
def create_mask(pred_mask): pred_mask = tf.argmax(pred_mask, axis=-1) pred_mask = pred_mask[..., tf.newaxis] return pred_mask[0] def show_predictions(dataset=None, num=i): if dataset: for image, mask in dataset.take(num): pred_mask = model.predict(image) display([image[0], mask[0], create_mask(pred_mask)]) else: display([sample_image, sample_mask, create_mask(model.predict(sample_image[tf.newaxis, ...]))]) show_predictions() 
The callback defined below is used to observe how the model improves while information technology is training.
class DisplayCallback(tf.keras.callbacks.Callback): def on_epoch_end(self, epoch, logs=None): clear_output(wait=True) show_predictions() print ('\nSample Prediction afterward epoch {}\n'.format(epoch+1)) EPOCHS = 20 VAL_SUBSPLITS = 5 VALIDATION_STEPS = info.splits['test'].num_examples//BATCH_SIZE//VAL_SUBSPLITS model_history = model.fit(train_batches, epochs=EPOCHS, steps_per_epoch=STEPS_PER_EPOCH, validation_steps=VALIDATION_STEPS, validation_data=test_batches, callbacks=[DisplayCallback()]) 
Sample Prediction after epoch twenty 57/57 [==============================] - 4s 62ms/pace - loss: 0.1838 - accuracy: 0.9187 - val_loss: 0.2797 - val_accuracy: 0.8955
loss = model_history.history['loss'] val_loss = model_history.history['val_loss'] plt.figure() plt.plot(model_history.epoch, loss, 'r', label='Preparation loss') plt.plot(model_history.epoch, val_loss, 'bo', label='Validation loss') plt.title('Training and Validation Loss') plt.xlabel('Epoch') plt.ylabel('Loss Value') plt.ylim([0, 1]) plt.legend() plt.show() 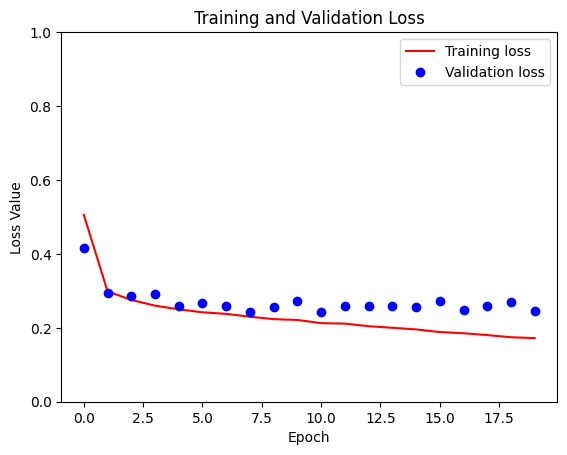
Brand predictions
Now, brand some predictions. In the interest of saving time, the number of epochs was kept minor, but you lot may set this higher to reach more accurate results.
show_predictions(test_batches, 3) 
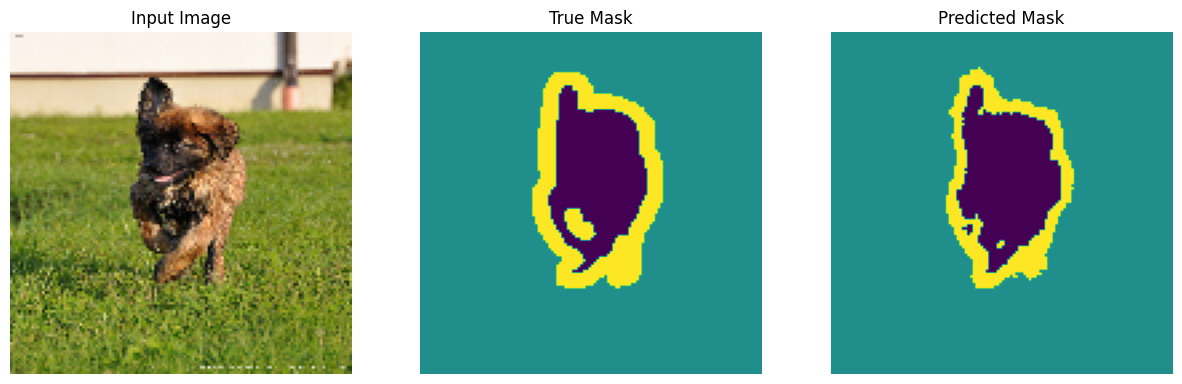

Optional: Imbalanced classes and grade weights
Semantic sectionalisation datasets can be highly imbalanced meaning that item class pixels tin be present more inside images than that of other classes. Since segmentation problems can exist treated as per-pixel classification problems, you can deal with the imbalance problem by weighing the loss function to account for this. It's a simple and elegant style to deal with this problem. Refer to the Classification on imbalanced information tutorial to learn more.
To avert ambiguity, Model.fit does non support the class_weight statement for inputs with 3+ dimensions.
effort: model_history = model.fit(train_batches, epochs=EPOCHS, steps_per_epoch=STEPS_PER_EPOCH, class_weight = {0:two.0, 1:2.0, 2:one.0}) assert False except Exception as e: print(f"Expected {type(e).__name__}: {e}") Expected ValueError: `class_weight` not supported for 3+ dimensional targets.
So, in this example you lot need to implement the weighting yourself. You'll do this using sample weights: In addition to (data, label) pairs, Model.fit also accepts (data, label, sample_weight) triples.
Model.fit propagates the sample_weight to the losses and metrics, which too have a sample_weight argument. The sample weight is multiplied by the sample's value before the reduction step. For example:
label = [0,0] prediction = [[-3., 0], [-3, 0]] sample_weight = [1, 10] loss = tf.losses.SparseCategoricalCrossentropy(from_logits=True, reduction=tf.losses.Reduction.NONE) loss(characterization, prediction, sample_weight).numpy() array([ 3.0485873, 30.485874 ], dtype=float32)
Then to make sample weights for this tutorial you need a part that takes a (data, label) pair and returns a (data, label, sample_weight) triple. Where the sample_weight is a 1-aqueduct image containing the class weight for each pixel.
The simplest possible implementation is to apply the characterization as an index into a class_weight list:
def add_sample_weights(epitome, label): # The weights for each class, with the constraint that: # sum(class_weights) == ane.0 class_weights = tf.constant([two.0, 2.0, one.0]) class_weights = class_weights/tf.reduce_sum(class_weights) # Create an image of `sample_weights` by using the label at each pixel every bit an # index into the `class weights` . sample_weights = tf.assemble(class_weights, indices=tf.bandage(label, tf.int32)) return image, characterization, sample_weights The resulting dataset elements contain 3 images each:
train_batches.map(add_sample_weights).element_spec (TensorSpec(shape=(None, 128, 128, 3), dtype=tf.float32, name=None), TensorSpec(shape=(None, 128, 128, 1), dtype=tf.float32, proper name=None), TensorSpec(shape=(None, 128, 128, 1), dtype=tf.float32, name=None))
At present you can train a model on this weighted dataset:
weighted_model = unet_model(OUTPUT_CLASSES) weighted_model.compile( optimizer='adam', loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True), metrics=['accuracy']) weighted_model.fit( train_batches.map(add_sample_weights), epochs=1, steps_per_epoch=ten) 10/10 [==============================] - 3s 44ms/pace - loss: 0.3099 - accurateness: 0.6063 <keras.callbacks.History at 0x7fa75d0f3e50>
Next steps
At present that you have an agreement of what image segmentation is and how it works, you can try this tutorial out with dissimilar intermediate layer outputs, or even unlike pretrained models. Yous may also claiming yourself past trying out the Carvana paradigm masking challenge hosted on Kaggle.
You may also want to come across the Tensorflow Object Detection API for another model you can retrain on your own information. Pretrained models are available on TensorFlow Hub
Source: https://www.tensorflow.org/tutorials/images/segmentation
0 Response to "Python Read in Png Image Normalize for Deep Neural Network"
Post a Comment